一次简单的机器学习实践,学了一些机器学习模型、文本处理、特征工程、超参数调优等,以及数据清理、特征提取、文本处理等处理大数据方法。
要求:对提供的训练集进行分析,通过特征工程、机器学习和深度学习等方法构建AI模型
由于之前没有机器学习的基础,因为本次实验参考了一些论文。一开始作为小白,是完全不懂这个要咋搞的,后来看了周志华的《机器学习》和《python大战机器学习》了解一下基础概念。像一些算法、模型的具体的原理其实了解一下大概就好放在代码里无非也就是一个函数的调用
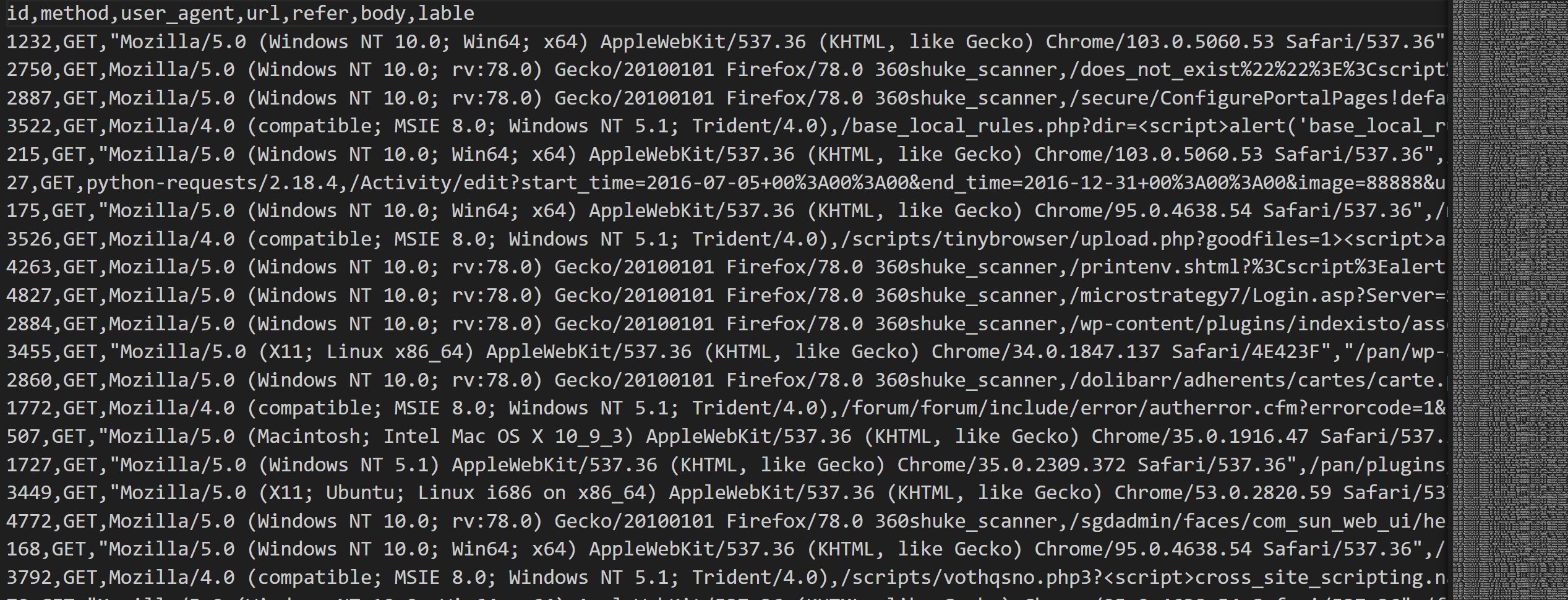
数据处理 观察数据集,可以看到有6种不同攻击类型的数据集,以及1个测试集,里面的访问请求就是正常抓包获得的请求,包含浏览器类型、user_id等
按照流程,首先进行数据处理,第一步通过正则匹配获取url中请求的参数
1 2 3 4 def get_url_query (s ):'[=&]' , urlparse(s)[4 ])return [li[i] for i in range (len (li)) if i % 2 == 1 ]
其次是将url解码,也就是将其中的特殊字符转化为%+数字的形式,略
还要匹配文件扩展名,也就是.后的字符(正则表达式学得不好)
1 return re.search(r'\.[a-z]+' , x).group()
user-agent信息提取:
1 2 3 4 'ua_short' ] = df['user_agent' ].apply(lambda x: x.split('/' )[0 ]) 'ua_first' ] = df['user_agent' ].apply(lambda x: x.split(' ' )[0 ])
用TF-IDF算法提取特征 在开始提取特征之前,首先还需要分析特征,这里由于给了6种不同类型的训练集,因此一开始我打算针对不同训练集分别进行特征提取
然鹅搞了一半觉得这样还是可能有考虑不到的地方….遂上网上找代码,发现网上的更简洁,一位大哥的思路是直接把数据集合并成一个,然后提取url查询参数、参数长度等共同特征,我心想原来如此,那我还搞个P啊,于是我也从简单的入手,直接6个数据集ctrl cv合并,然后代码一焯提取共同特征:
1 2 3 4 5 6 7 'url_query' ] = df['url_unquote' ].apply(lambda x: get_url_query(x)) 'url_query_num' ] = df['url_query' ].apply(len ) 'url_query_max_len' ] = df['url_query' ].apply(find_max_str_length) 'url_query_len_std' ] = df['url_query' ].apply(find_str_length_std) 'url_path_len' ] = df['url_path' ].apply(len ) 'url_path_num' ] = df['url_path' ].apply(lambda x: len (re.findall('/' , x)))
然后就是提取特征了
1 2 3 4 5 6 7 8 9 10 11 12 13 def add_tfidf_feats (df, col, n_components=16 ): list (df[col].values)1 ,'char_wb' ,1 , 2 ), for i in range (n_components):f'{col} _tfidf_{i} ' ] = X_svd[:, i]return df
创建一个TF-IDF对象 tf,然后给定参数,比如n_components用于指定截断奇异值分解后所保留的奇异值个数,也就是要将原始的 TF-IDF 特征矩阵降维到的维度数量,具体这块涉及算法
有些特征后续是8需要考虑的,比如’id’, ‘user_agent’, ‘url’, ‘body’, ‘url_unquote’, ‘url_query’, ‘url_path’, ‘label’这些
利用lightGBM开始训练 用lightGBM模型训练,起码要了解K折交叉验证对象的含义,才能选择参数填进去
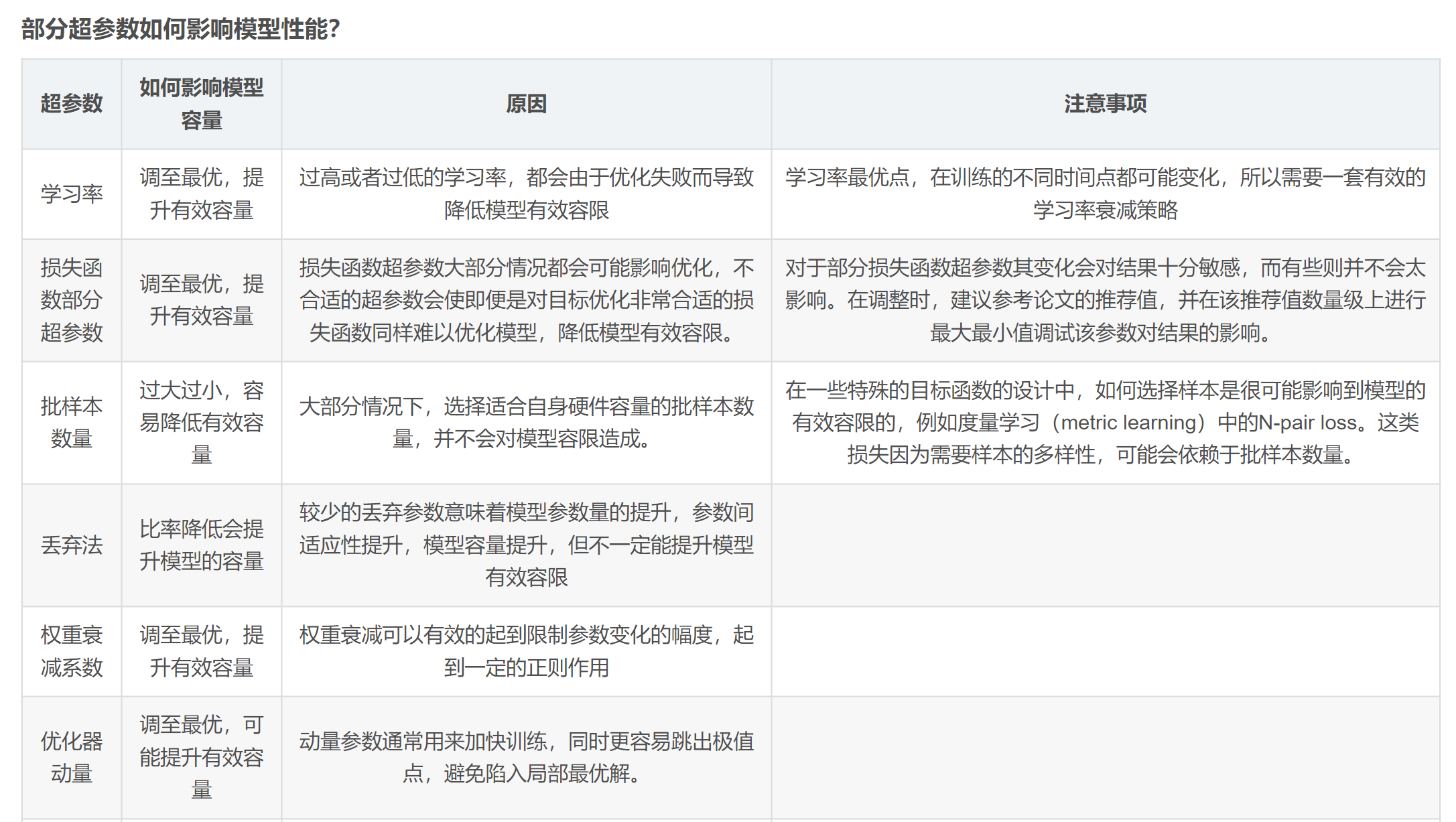
好,肥肠简单是不是,然后进入超参数调优环节:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 learning_rate:学习率,控制每次迭代中模型参数更新的步长。较小的学习率可以提高模型在训练集上的稳定性,但可能需要更多的迭代次数才能达到最优解。multiclass,表示多分类问题,模型会输出每个类别的概率分布。 multiclass,表示多分类问题。 bagging_fraction:样本采样比例,用于控制每次迭代中随机选择的样本比例。也是为了减少过拟合。 bagging_freq:样本采样频率,指定了进行样本采样的频率。设置为2表示每两次迭代进行一次样本采样。 1 表示使用所有可用的 CPU 核心进行并行计算。1 表示不输出任何信息,通常用于静默模式。
哈哈哈看不懂寄了(bushi)
睡觉了,完了再更